Когда компания растет высокими темпами, зачастую возникает потребность собирать большое количество данных, для их последующего анализа.
Мы часто запускаем новые проекты, направления, тесты. Например, нужно собрать данные для очень специфической задачи.
Задача сделать решение, которое смогло бы максимально универсально и эффективно, и в тоже время быстро принимать различные данные. От выручки до логов на бекендах.
Laughingbird Software The Graphics CreatorГлавные задачи которые мы поставили перед собой:
- Идемпотентность данных
- Отказоустойчивость системы
- Масштабируемость всех частей системы
- Failover
- Возможность останавливать части системы, для их модернизации или профилактики
- Сбор данных должен быть универсальным для всех платформ, проектов, задач
- Иметь возможность отправлять зашифрованные данные
- Удобная кастомизация метрик, удобство в добавления разных разрезов к данным
- Возможность принимать данные максимально эффективно из разных частей мира
- Отображение данных в режиме Realtime (<2s).
Так как, к-во событий будет исчисляться сотнями миллионов в сутки, потенциально и миллиардами, необходимо использовать систему, которая будет иметь возможность буферизировать, сжимать, подготавливать данные.
Итого, мы собрали все необходимые инструменты:
- GEO-dns (Route53)
- OpenResty (Nginx+Lua)
- Kafka+Zookeeper
- Consumer tasks (PHP)
- ClickHouse
- Supervisor
- Mysql для словарей , определения проектов , метрик.

Для начала нам нужна точка входа в систему – место куда будем отправлять данные. Также, необходимо понимать, что скорость подключения и отправки данных к одному серверу из разных стран будет заметно разной, учитывая расстояния и особенности построения мировой сети.
Выбор пал на сервис от Amazon Route53, он же GEO-dns в нашем случае. Есть много других подобных провайдеров. Но у нас уже был успешный опыт работы именно с Route53, который также имеет возможность сделать Failover на случай падения сервера. Это необходимый функционал в построении высоконагруженных систем.
- Направляем наш домен на Route53
- Создаем записи “A” с учетом геолокации
- Направляем их на все наши входящие в первое звено сервера
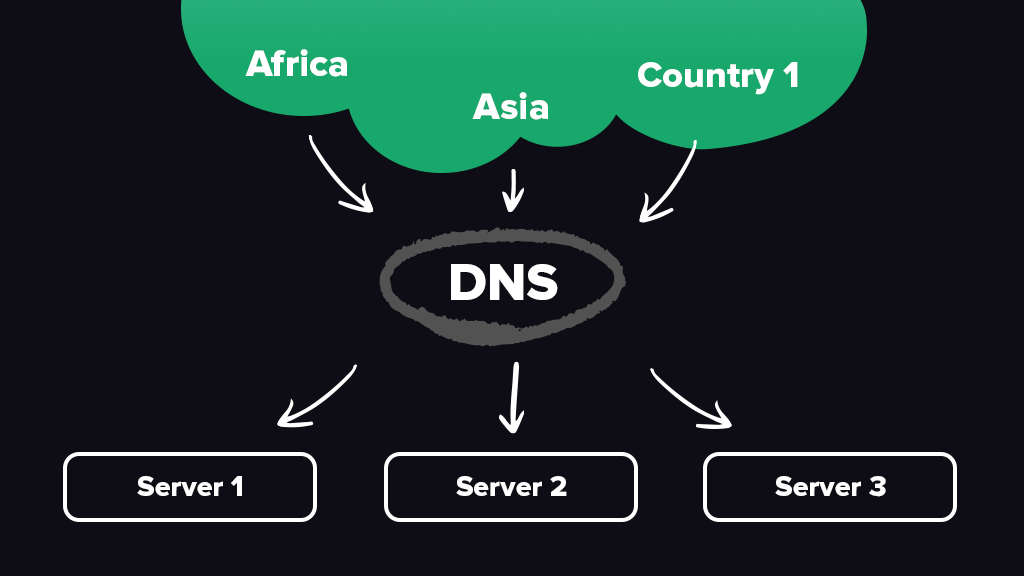
Имеем
- Балансировщик – done
- Failover – done
- На каждое Гео свои сервера – done.
Первым звеном в системе использовали OpenResty. Для чего?
По сути это тот же любимый многими веб-сервер Nginx, но со встроенным модулем Lua, который нужен нам для буферизации данных и для оптимизации скорости. Данные приняли в систему максимально быстро и отправили на клиент код 200.
- Собираем данные в пачки
- Добавляем базовую информацию о запросе (например GEO идентификация по IP)
- Архивируем пачки
- Отправляем данные на сервера с Kafka
- И это все в памяти, без использования медленных дисков.
Очередь в Kafka можно делить на партиции. Например, десять партиций с тройной репликацией. Это позволит сохранить данные даже при отказе не одного, а многих серверов в кластере. Но минусом будет конечно же избыточность. Так как, данные будут сохранены в трех копиях.
Первый и самый главный этап закончен. Данные успешно были приняты в систему для последующей обработки.
Связка Kafka+Zookeeper получилась очень удачной, так как стабильность их работы в кластере показала себя более чем удовлетворительной.
Далее нужно обработать данные, разложить по проектам и метрикам таким образом, чтобы иметь удобную возможность принимать решения на их основе, либо закрывать другие задачи, мониторинг и т.д.
Почему выбор пал на ClickHouse как хранилище?
- Это колоночная БД, а это значит, что каждая колонка в таблице представлена в файловой системе как отдельный файл. Это удобно когда у нас нету определенный структуры данных и в некотором будущем структура будет меняться. Например, когда нужно добавить новый разрез к уже существующей метрике.
- Данные соединяются (merge) к старым на фоне, как следствие имеем возможность быстро данные отправлять, и не ждать реальной вставки на диски.
- Есть возможность сохранять свежие данные (последние) на SSD или NVM дисках, а уже более старые (например недельной давности) отправлять на большие HDD диски. Это в свою очередь удешевляет цену сохранности данных. Этот процесс также отрабатывает на фоне.
- Opensource проект, его постоянное развитие.
- Куча встроенных аналитических функций.
- Родной SQL с минимальными отличиями.
- Возможность делать materialized views, когда нужно делать представление данных как результат работы запроса (select).
- Масштабируемость. Distributed таблицы, те которые по сути не имеют в себе данных. А при выборке из них делают распределено на всех шардах.
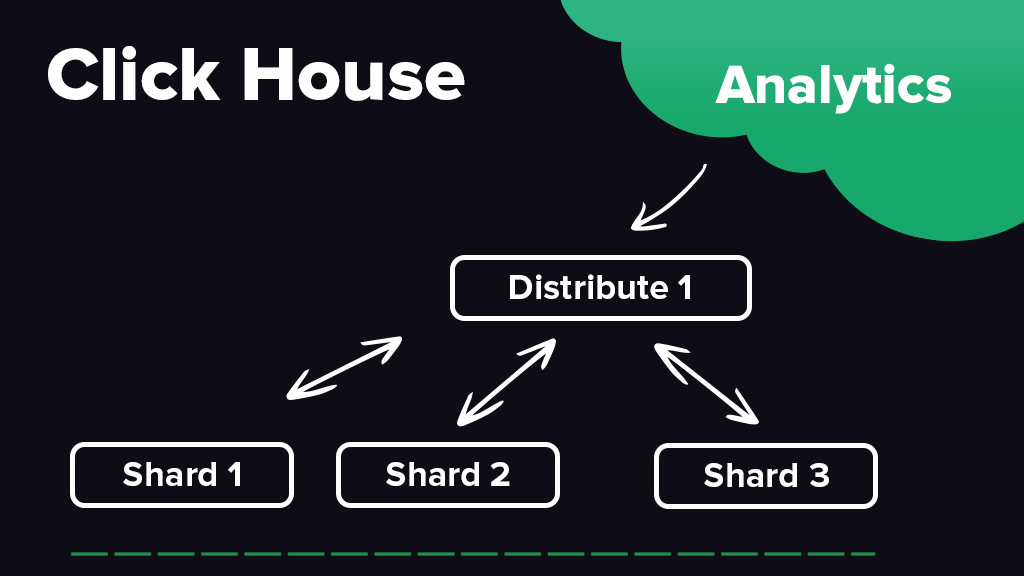
Данные мы представили в очень удобном виде:
- Наш виртуальный проект – это база данных
- Каждая метрика – это таблица
- Каждый разрез метрики – это колонка
- Все сохраняемые данные – денормализованные, это позволит на больших объемах делать быстрые выборки.

PHP. Таски.
Да, за основу обработки данных мы взяли конечно же PHP, так как опыт работы с ним у нас достаточный для решения почти любых задач.
- Стягиваем данные из Kafka пачками
- Достаем оригинал из архива
- Если данные были изначально зашифрованы, расшифровываем
- Определяем проект, принадлежность к конкретной метрике
- Группируем данные по проекту, метрике
- Создаем БД в Clickhouse, если такой еще нет
- Если были добавлены новые поля к метрикам, добавляем к таблице колонку (делаем alter table)
- И отправляем уже обработанные, сгруппированные данные в Clickhouse хранилище
Таких обработчиков необходимо запустить такое к-во как и к-во партиций в очереди Kafka. Так как каждая партиция обрабатывается своей таской.
Готово. Тестируем и чувствуем себя превосходно!